Solution Recall – Zugfolgenkombination als Schlüssel zur Cube-Optimierung
Das Skript Solution Recall setzt genau dort an, wo frühere Ansätze aufgehört haben – es kombiniert gelernte Einzelzüge zu Zugfolgenkombinationen und lässt dem Zufall freien Lauf, um den Rubik’s Cube optimal zu lösen. Der Würfelzustand wird zunächst aus einer CSV-Datei geladen und kann, falls gewünscht, durch zufällige Bewegungen gemischt werden. Anschließend werden die gespeicherten Zugfolgen aus Improvements.csv zu diversen Kombinationen zusammengefügt. Diese werden dann in jedem Durchlauf zufällig ausgewählt und auf den aktuellen Zustand angewendet, um schrittweise immer mehr von den 20 beweglichen Steinen korrekt zu positionieren und zu orientieren. Bei jeder Iteration prüft das Skript, ob sich der Zustand verbessert hat – erreicht es die Lösung, wird der exakte Zugfolgenverlauf dokumentiert und der Würfel zurückgesetzt, um weitere Varianten zu erkunden. Alle relevanten Kennzahlen, wie Iterationsanzahl, angewendete Zugfolgen, Laufzeit und Ausgangszustand, werden fortlaufend protokolliert und abschließend in einer Ergebnisdatei abgelegt.
Ergebnis
Im überarbeiteten Skript wurde die komplette Zufallskomponente für die Generierung neuer Zugfolgen entfernt. Stattdessen greift der Algorithmus ausschließlich auf eine vordefinierte Datenbank zuvor gelernter Zugsequenzen zurück. Sobald eine Sequenz angewandt wurde, bewertet das Programm deren Effekt auf den aktuellen Würfelzustand und übernimmt die Änderung nur, wenn sich dadurch der Fortschritt in Richtung Lösung tatsächlich verbessert. Dieser Ansatz stellt sicher, dass keine vollkommen unbewährten, zufälligen Züge mehr ausprobiert werden und reduziert die Suche auf einen konkreten, validierten Suchraum.
Gleichzeitig wurde ein Mechanismus integriert, der „hängenbleibende“ Runs abfängt: Erkennt die Verbesserungsschleife an irgendeiner Stelle, dass keine weitere Optimierung möglich ist – also keine der vorhandenen Zugfolgen eine günstigere Konfiguration herbeiführt –, bricht das Skript den aktuellen Run ab und startet sofort mit einer neuen, zufällig ausgewählten Kombination aus gelernten Zugfolgen. Dadurch wird verhindert, dass sich das Programm endlos in einer Sackgasse festfährt.
In der Praxis führte dieses Vorgehen zu einer hohen Erfolgsquote: In etwa 90 % aller Durchläufe konnte das Skript eine vollständige Würfellösung erreichen. Häufig wurden sogar mehrere unabhängige Lösungswege hintereinander gefunden, da die Schleife nach erfolgreichem Abschluss einer Sequenz automatisch mit einer weiteren Kombination neu beginnt. Die Laufzeit pro erfolgreichem Run blieb dabei überraschend gering, da erprobte Zugfolgen meist schnell zu einer lösbaren Stellung führen.
Allerdings traten in rund 10 % der Runs Fälle auf, in denen trotz unzähliger Iterationen keine Lösung gefunden wurde. Hier offenbarte sich eine Einschränkung der aktuellen Datenbank: Bestimmte Zwischenschritte oder „Lücken“ in den gelernten Zugfolgen fehlen, sodass das Programm rein formal gar nicht mehr in der Lage ist, die optimale Fortsetzung zu wählen. Diese Runs enden erst dann, wenn der Algorithmus erkennt, dass keinerlei Verbesserung mehr möglich ist, und somit kein weiterer Fortschritt erzielt werden kann.
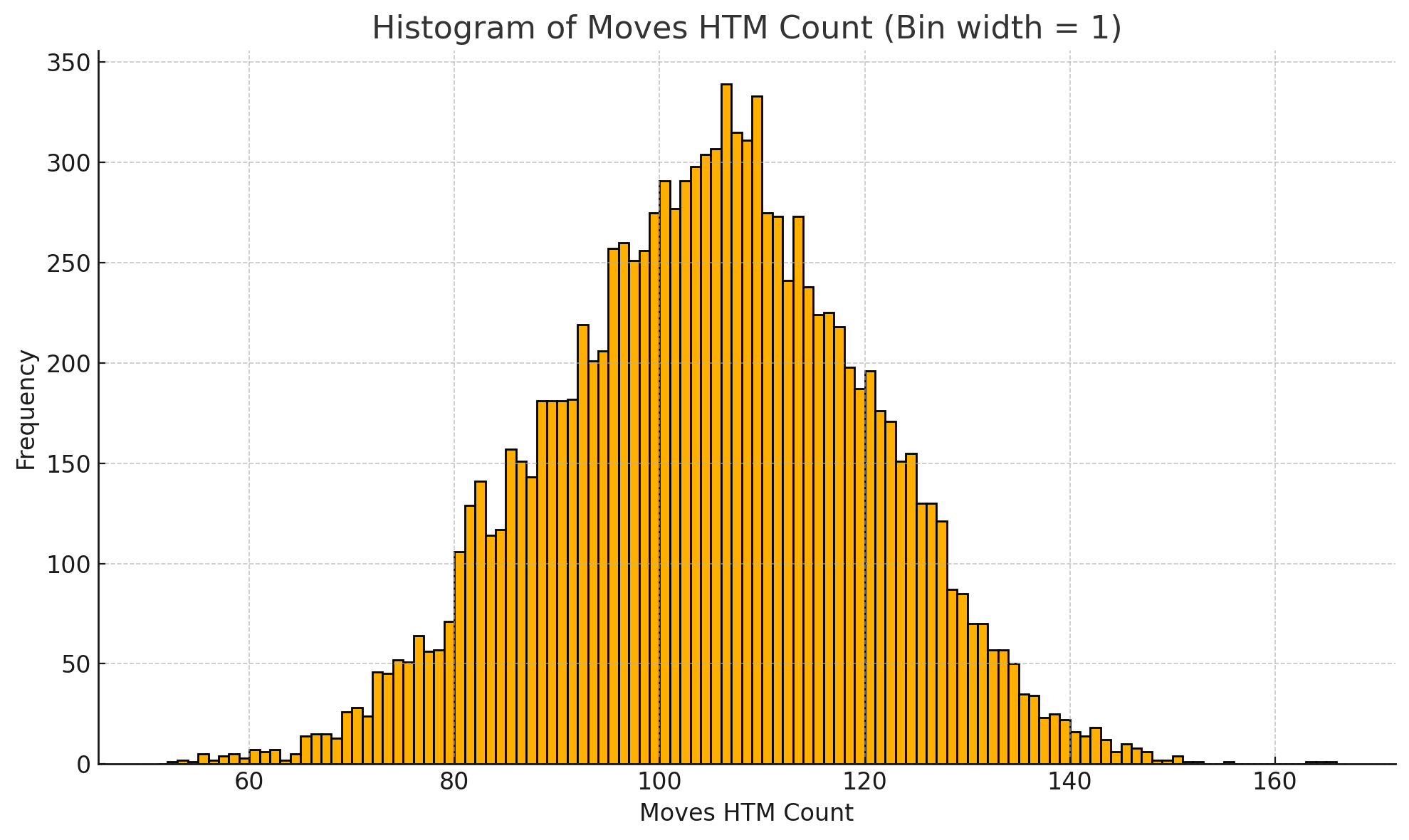
In statistischer Hinsicht haben sich mit der Entfernung zufälliger Züge die durchschnittliche Zugzahl und der maximale Zugaufwand pro Lösung erhöht, während sich die minimale Zuganzahl leicht verbessert hat. Die Optimierungsziele sind damit weniger aggressiv als zuvor, als noch per Zufallsgenerator alle denkbaren Permutationen getestet wurden. Das Ergebnis ist allerdings robuster: Aus nahezu jeder Ausgangstellung wird schnell eine valide, vollständige Lösung gefunden, selbst wenn sie nicht immer die kürzestmögliche ist.
Zusammenfassend lässt sich sagen, dass das aktuelle Skript einen zufriedenstellenden Kompromiss bietet. Es liefert in der Mehrzahl der Fälle eine komplette Rubik’s-Cube-Lösung, ohne sich in endlosen Iterationen zu verlieren, und nutzt dabei ausschließlich bewährte Zugfolgen. Eine 100 %ige Abdeckung aller möglichen Startstellungen bleibt zwar unerreicht, war aber aufgrund der vorhandenen Zugdatenbank auch nicht zwingend das Ziel. Für die Weiterentwicklung würde es sich empfehlen, gezielt fehlende Sequenzen zu identifizieren und die Datenbank zu ergänzen, bevor man erneut über eine vollständige Abdeckung nachdenkt.
Ressourcen
Notwendig für die Skriptausführung
- Skript_03: SolutionRecall.py
- Parameterdatei: parameter_csv-Parameter.csv
- Mappingdatei der Züge: mappings.json
- Importdatei mit Startposition: csv_export-StartPos.csv
- Datei mit den gelernten Zügen: Improvements.csv
Optional
- Skript zur Erstellung Startposition: CreateStartPosition.py
- Testskript zur Verifikation der Lösung: TestMoves.py